| Exchange and combination of annotations | ||
|---|---|---|
 | Chapter 3. Resource annotations |  |
| Exchange and combination of annotations | ||
|---|---|---|
| | Chapter 3. Resource annotations | |
Nearly every resource (corpus or automatic annotation tool) comes with its own annotation scheme, one or more tagsets, and one or more possible representation formats. However, this multitude of formats, schemes, tagsets and underlying categorial distinctions is a serious obstacle to the further processing and querying of heterogeneous resources, which is a likely scenario within a research infrastructure like CLARIN-D.
In this section, we present an example of a generic exchange format for annotations, which can be used with respect to different representation formats, we refer to the data category registry from Chapter 1, Concepts and data categories to relate tagsets and we give an overview on how the transfer of annotation schemes between different concepts has been handled so far.
Due to a number of different representation formats for annotations, varying from basic inline formats to task-specifically tailored XML descriptions, the exchange of annotated data often poses a problem. Therefore, structurally generic representations, which do not implement a preference for a specific linguistc theory, are needed to serve as pivot formats in the conversion procedure from one specific representation into another one, such as formats proposed by TEI and ISO. For a complete overview of all standards exploited in CLARIN-D and their relations see the CLARIN-D standards guidance web page. Since direct conversion often means to build a lot of single converters and on top of that probably also loss of information, an exchange format should be able to keep as much information as possible from the input while only passing the relevant parts to the output format.
In the following section we describe one of those possible pivot formats, the Linguistic annotation format (LAF, [ISO 24612:2012], see also [Hinrichs/Vogel 2010]). LAF uses a simple graph structure as data model for the stand-off annotation layers which is generic enough to handle different annotations. Some examples for annotation layers such as part-of-speech and syntax are provided in the next sections. Other annotation layers can be represented as well. LAF is also an ISO standard and therefore fits well into the CLARIN objective of taking standards into account.
LAF is developed by the ISO technical committee 37 (ISO/TC 37/SC 4), and is related to other standards developed within this group such as [ISO 12620:2009] on specification and management of data categories for language resources and [ISO 24610-1:2006] on feature structure representation. LAF provides a data model to represent primary data and different kinds of linguistic annotations without commitment to one particular linguistic theory. It is based on stand-off annotations where each annotation layer may contain references to elements in other layers.
There is always at least one segmentation layer, which, as a result of a segmentation process, defines the parts of the resource that may be further annotated. As different annotations may refer to the resource with different granularity, it is also possible to have concurrent segmentation layers for the same primary data.
While trying to leave the original resource untouched, the encoding plays a crucial role for the references into the primary data. Positions in the primary data are for example defined in between byte sequences denoting the base unit of representation. These positions are referred to as virtual nodes. The byte sequence defines the minimal granularity for the parts to be annotated. For textual data (UTF-8 encoded by default), virtual nodes are located between each pair of adjacent characters of the primary data document. Anchors refer to these virtual nodes. Example 3.7, “LAF virtual nodes” shows the virtual nodes defined between the characters.
|h|i|s| |o|w|n| |w|e|b|s|i|t|e| 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
Node numbers are to be read top-down. Anchors to node 568 and 575, e.g., denote the token website. Anchors to the nodes 567 and 568 denote a whitespace.
LAF stipulates an XML-serialization as pivot format, which currently focuses on textual data. Nevertheless, by utilizing the flexible anchor management for references into primary data, LAF is designed to handle other types of media as well, e.g. audio data referenced by timestamps.
The XML-serialization of the LAF pivot format is called Graph annotation format(GrAF). It is based on graph data structures and includes nodes, edges, regions for referencing primary data, and annotations which can consist of simple labels or complete feature structures (see [ISO 24610-1:2006]). Therefore annotations at different levels of complexity can be represented [Ide/Suderman 2007].
The following examples of a segmentation and some annotation documents are extracted from the MASC I Corpus. MASC structure and annotation details are taken from the MASC documentation website.
In a segmentation, regions of primary data are denoted by anchors. In Example 3.8, “LAF reference to virtual nodes” the anchors refer to the virtual nodes in example Example 3.7, “LAF virtual nodes”, so seg-r194 denotes the token his, seg-r196 the token own and seg-r198 the token website respectively.
<region xml:id="seg-r194" anchors="560 563"/> <region xml:id="seg-r196" anchors="564 567"/> <region xml:id="seg-r198" anchors="568 575"/>
In an annotation document, nodes, edges and annotations can also be specified. A terminal node, i.e., a node with a direct reference to the primary data, references a region with a link and the respective annotations reference the node or edge element they belong to. Non-consecutive parts of the primary data can be annotated by introducing a region for each part and referencing them conjointly in the graph structure layered over the segmentation. Example 3.9, “LAF part-of-speech annotation” reproduces a part-of-speech annotation from the Penn Treebank project of the region denoting website.
<node xml:id="ptb-n00198">
<link targets="seg-r198"/>
</node>
<a label="tok" ref="ptb-n00198" as="PTB">
<fs>
<f name="msd" value="NN"/>
</fs>
</a>Edges in annotation documents denote their source node and target node with
from and to attributes. The node
referenced by the edge attributes can also be defined in another annotation
document. In this case the annotation document containing the edge depends on
the annotation document containing the referenced node. In Example 3.10, “LAF syntactic annotation”
his own website constitutes a noun phrase, i.e., the
category NP is annotated to the node with the identifier
ptb-n00195. This syntactic annotation (from the Penn
Treebank project) depends on the part-of-speech annotation in Example 3.9, “LAF part-of-speech annotation”. The node ptb-n00198
from Example 3.9, “LAF part-of-speech annotation” is annotated as
NN, and referenced as the target of the edge in Example 3.10, “LAF syntactic annotation” .
<node xml:id="ptb-n00195"/>
<a label="NP" ref="ptb-n00195" as="PTB">
<fs>
<f name="cat" value="NP"/>
</fs>
</a>
<edge xml:id="ptb-e00192" from="ptb-n00195" to="ptb-n00198"/>
<!-- website -->
Example 3.11, “LAF event annotation” reproduces an annotation for events produced by researchers at Carnegie-Mellon University. This annotation excerpt refers to the example sentence: He said companies [..] would be able to set up offices, employ staff and own equipment [..]. It denotes a setting up event with two arguments.
<region xml:id="ev-r4" anchors="894 900"/>
<node xml:id="ev-n4">
<link targets="ev-r4"/>
</node>
<a label="Setting Up" ref="ev-n4" as="xces">
<fs>
<f name="arg1" value="companies"/>
<f name="arg2" value="offices"/>
</fs>
</a>We describe the LAF/GrAF framework here, because it can take different annotation layers into account. Within ISO technical committee 37 (ISO/TC 37/SC 4) there are also standards (and upcoming standards) related to specific annotation layers, such as the Syntactic annotation framework (SynAF, [ISO 24615:2010].
Users can transform their data format into the LAF pivot format GrAF, and from GrAF into any other format for which an importer or exporter exists. There is ISO GrAF, an experimental Java API provided to access and manipulate GrAF annotations, and a renderer for the GraphViz visualization.
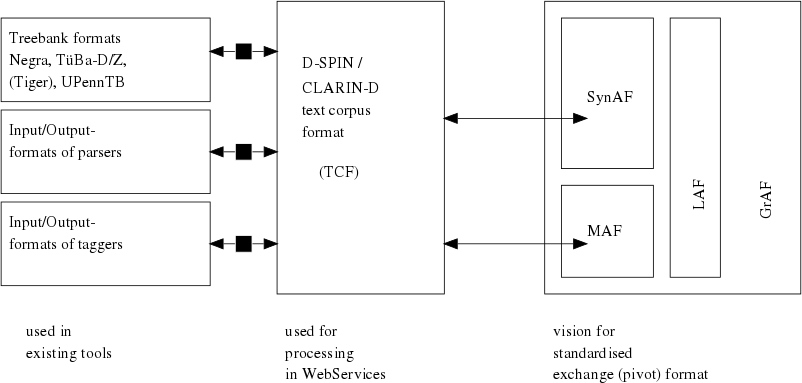
In terms of the WebLicht tool chains (see the section called “WebLicht – A service-oriented architecture for linguistic resources and tools”), internal representations of existing tools should not have to be changed in order to integrate them into the architecture. A 3-layer-framework, which differentiates between tool format, processing format and exchange format is proposed. Figure 3.1, “The 3-layer-framework” outlines the idea.
To make a web service out of an existing tool, the tool is encapsulated in a wrapper, see Chapter 8, Web services: Accessing and using linguistic tools. While the tools still work internally using their own representations, the wrapper provides an interface converting the output into a common processing format for the web service chains, e.g. TCF in the case of WebLicht. Note that a processing format has to fulfill other requirements than an exchange format, being as efficient as possible while staying as faithful to the original content as neccessary. After the web service chain has been processed the data could again be converted into an exchange format taking standard formats such as LAF or TEI into account.
The counterpart for a generic exchange format with respect to annotation representation is a data category registry for annotation content, i.e., for defining relationship between the categories used in the different tagsets. The problems which arise with this approach will be shortly discussed here. For a more detailed discussion see Chapter 1, Concepts and data categories, which describes the objectives of a data category registry and introduces ISOcat as the data category registry utilized in CLARIN-D.
In the case of different tagsets, e.g. STTS for annotating part-of-speech in German data or
the Penn Treebank tagsets for part-of-speech and syntactic phrases with respect to
(American) English, we might have to deal with a number of mismatches or
“misunderstandings” due to different conceptions. Some examples are
granularity, existence or duplication. Tagsets may differ in granularity. E.g. in
STTS, there are two tags for nouns, one for common nouns and one for proper names,
while in the Penn Treebank tagset nouns are additionally classified according to
their number (four tags). If we compare different tagsets we may come upon cases
where a certain category will be present in one tagset, but completely absent in another.
Please note that we are not comparing linguistic concepts here, but sticking to the actual
information annotated. Duplication means that there are the same tags, meaning something
different or different tags meaning the same. For example, according to the
granularity example above, NN is a common noun in STTS but a non-plural common noun
in terms of the Penn Treebank tagset.
While generic representation formats allow for an exchange of annotated resources and data category specifications help relating the semantics of single tags, much more needs to be considered when one annotation should be completely transformed into another one which relies on a different annotation scheme. This usually comes at the cost of either loosing information or being forced to generate new information.
A prominent example is the conversion from constituency-based into dependency-based syntax. While on the one hand some information may potentionally be lost in the process, on the other hand the heads in dependency-based annotation have to be explicitly specified in the transformation. As they cannot always be clearly identified, e.g. in English noun phrases containing compounds, additional procedures are needed. Head identification can then be conducted manually or by utilizing heuristics, see [Yamada/Matsumoto 2003], [Collins 1997], [Magerman 1994]. A heuristic approach may add errors to the annotation. However, as such conversions are often done in terms of shared tasks or statistical parsing approaches, a large amount of data is needed, which makes a manual approach rather impractical.
Another approach to large-scale mapping of annotation schemes considers ontologies of annotations such as in [Chiarcos 2008]. The ontologies again can be used to link to data category registries, e.g. ISOcat, see [Chiarcos 2010].
| |  | |
| Aspects of annotations |  | ToC | ToC | Recommendations |