| Aggregation | ||
|---|---|---|
 | Chapter 2. Metadata |  |
| Aggregation | ||
|---|---|---|
| | Chapter 2. Metadata | |
The wish to have a central catalog covering metadata aggregated from different repositories has led to the emergence of the Open Archives Initiative's protocol for metadata harvesting (OAI-PMH) as a de-facto standard for gathering metadata into a single catalog – a process that is called metadata harvesting.
In the OAI-PMH model the world is divided in data providers, that offer metadata for harvesting, and service providers that harvest the metadata and offer discovery service to the world, for instance a central metadata catalog. The OAI-PMH protocol is fairly efficient and simple to implement. Each data center that is offering linguistic resources should offer metadata descriptions that can be harvested by service providers – for CLARIN centers it is mandatory to support the OAI-PMH protocol.
OAI-PMH requires that the metadata is in all cases also offered in DC format next to any other format such as for example CMDI. This allows that metadata from different disciplines can be harvested and put into one catalog although presumably much information will be lost by mapping all metadata to the rather simple and restricted DC set. When all harvested data providers have agreed to also provide metadata of another set than DC, it is of course possible to create a more useful catalog.
Gathering all CMDI metadata into one large basket does not make sense without an intuitive interface to search and explore the information that it contains. In the case of CLARIN the metadata provided by the centers in the CMDI format is harvested via OAI-PMH and then made accessible via the Virtual Language Observatory (VLO). More details on the harvesting process employed by the VLO can be found on the CLARIN EU website. Anyone else can also build a portal based on the same principles. However, it should be noticed that aggregating and mapping metadata from different service providers in general does involve much curation effort.
With the VLO's facet browser it is possible to quickly navigate through this constantly growing inventory of language resource (and tools) metadata. Using a full-text search one can quickly identify electronic and non-electronic sources of information. The results can also be refined step-by-step by specifying a particular language, collection, resource type, subject and so on. While the VLO is not a tool by itself that can directly answer research questions it allows any user with an Internet connection to efficiently search within a metadata catalogue, as to identify language resources and tools that might be helpful for research purposes. As such it can serve as leverage for the reuse of data sets and archived language material in general.
Suppose a multidisciplinary research team of historians, linguists and cultural psychologists is investigating sign language iconicity in the context of the fall of the Berlin wall. Figure 2.8, “Using the VLO to identify relevant language resources” and Figure 2.9, “Accessing the results of a VLO query” illustrate how the VLO can be used to explore some of the resources that might be relevant for such a study.
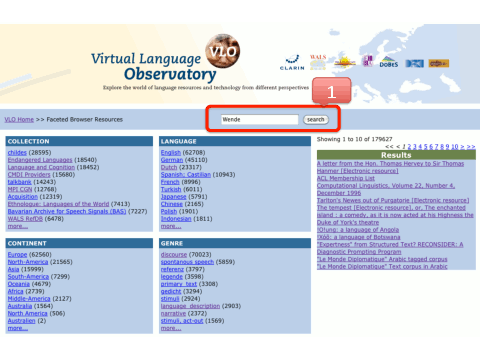 |
A full text metadata search on the word “Wende” returns 23 results (out of 179.000)
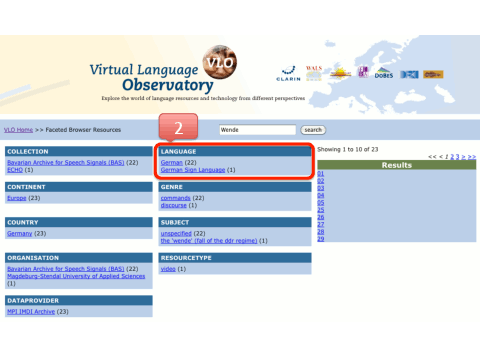 |
This set is narrowed down to 1 result when selecting only the results that are about German Sign Language
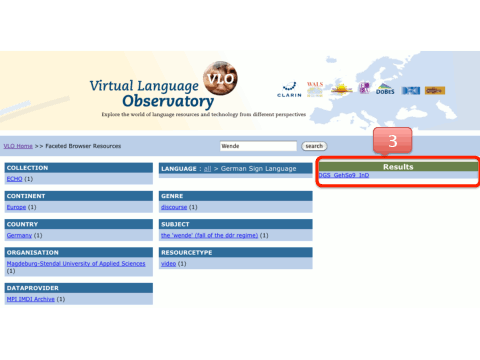 |
The user clicks on this single result to view the details of the metadata
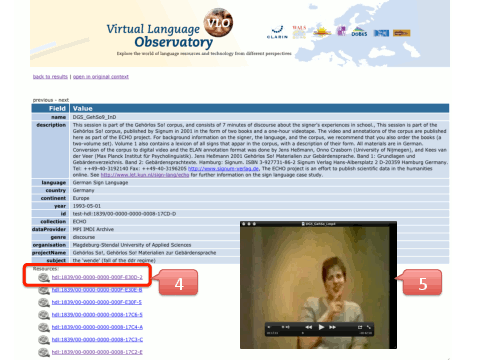 |
A user clicks on one of the metadata-described resources and can inspect it
| |  | |
| The Component Metadata Initiative (CMDI) |  | ToC | ToC | Recommendations |