| Hierarchies of linguistic tools | ||
|---|---|---|
 | Chapter 7. Linguistic tools |  |
| Hierarchies of linguistic tools | ||
|---|---|---|
| | Chapter 7. Linguistic tools | |
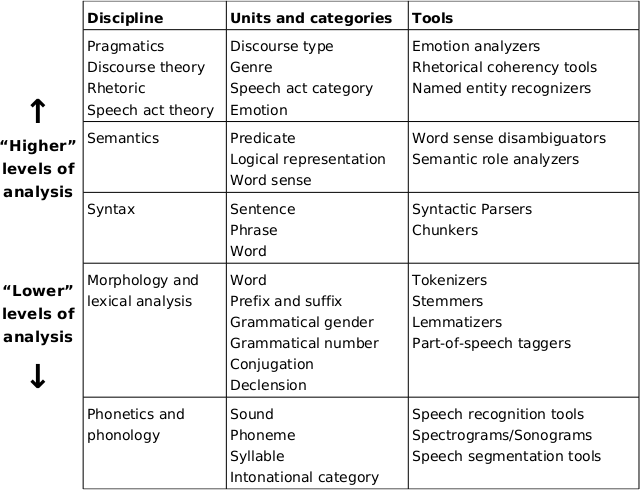
Linguistic tools are often interdependent and frequently incorporate some elements of linguistic theory. Modern linguistics draws on traditions of structuralism, a school of thought in the humanities and social sciences dating to the early 20th century. Structuralism emphasized the study of phenomena as hierarchal systems of elements, organized into different levels of analysis, each with their own units, rules, and methodologies. In general, linguists organize their theories in ways that show structuralist influences, although many disclaim any attachment to structuralism. Linguists disagree about what levels of analysis exist, what units are appropriate to each level, to what degree different languages might have differently organized systems of units and levels, and how those levels interrelate. However, hierarchal systems of units and levels of analysis are a part of almost all linguistic theories and are very clearly reflected in the practices of computational linguists.
Linguistic tools are usually categorized by the level of analysis they perform, and different tools may operate at different levels and over different units. There are often hierarchal interdependencies between tools. A tool used to perform analysis at one level often requires, as input, the results of an analysis at a lower level.
Figure 7.1, “A hierarchy of levels of linguistic analysis” is a very simplified hierarchy of linguistic units, sub-disciplines and tools – which is why “higher” and “lower” are in quotes. It does not provide a complete picture of linguistics and it is not necessarily representative of any specific linguistic school, nor should any implication about the complexity or importance of particular levels of analysis be taken from this scheme. However, it provides an outline and a reference framework for understanding the way hierarchal dependencies between levels of analysis affect linguistic theories and tools: Higher levels of analysis generally depend on lower ones.
Syntactic analysis like parsing usually requires words to be clearly delineated and part-of-speech tagging or morphological analysis to be performed first. This means, in practice, that texts must be tokenized, their sentences clearly separated from each other, and their morphological properties analyzed before parsing can begin. In the same way, semantic analysis is often dependent on identifying the syntactic relationships between words and other elements, and inputs to semantic analysis tools are often the outputs of parsers.
However, this simplistic picture has many important exceptions. Lower level phenomena often have dependencies on higher level ones. Correctly identifying the part-of-speech, lemmas, and morphological categories of words may depend on a syntactic analysis. Morphological and syntactic analysis can affect phonetic analysis: Without information from higher in the hierarchy, it can be impossible to tell the difference between “I recognize speech” and “I wreck a nice beach” [Lieberman et al. 2005]. Even speech recognition – one of the lowest level tasks – depends strongly on knowledge of the semantic and pragmatic context of speech.
Furthermore, there is no level of analysis for which all linguists agree on a single standard set of units of analysis or annotation scheme. For example, the Penn Treebank and the British National Corpus use different part-of-speech tags. Different tools will have radically different inputs and outputs depending on the theoretical traditions and commitments of their developers.
Most tools are also language specific. There are few functional generalizations between languages that can be used to develop single tools that apply to multiple languages. Different countries with different languages often have very different indigenous traditions of linguistic analysis, and different linguistic theories are popular in different places, so it is not possible to assume that tools doing the same task for different languages will necessarily be very similar in inputs or outputs.
Corpus and computational linguists most often work with written texts, partly because written texts do not usually require phonetic analysis and are easy to find in large quantities, and partly because computational tools are much easier to obtain for written language than speech or other forms of communication. This chapter will not discuss speech recognition and phonetic analysis tools suitable for dealing directly with speech because very few of them are currently part of the CLARIN-D infrastructure, although some of the multimedia tools described here are suitable for some kinds of phonetic analysis. Most tools assume that their inputs are written language data in specified data storage formats.
Furthermore, at the highest levels of analysis, tools are very specialized and standardization is rare, so few tools for very high linguistic levels are discussed here. CLARIN-D is, however, committed to support for all varieties of linguistic tools, and expects to provide more resources at all levels of analysis as the project develops.
| |  | |
| Chapter 7. Linguistic tools |  | ToC | ToC | Automatic and manual analysis tools |