| Automatic segmentation and annotation tools | ||
|---|---|---|
 | Chapter 7. Linguistic tools |  |
| Automatic segmentation and annotation tools | ||
|---|---|---|
| | Chapter 7. Linguistic tools | |
The tools described in this section operate without very much direct user interaction, producing an annotated or segmented resource as its output. Many of them require training and may be available already trained for some tasks, or be available for users to train to suit their needs.
Those tools which are presently available through WebLicht – CLARIN-D's web
service-based linguistic workflow and tool execution enviroment – are marked
with a small icon: 
The tools listed here are not an exhaustive list of WebLicht-accessible tools, and as the service grows, more tools will be integrated. For a current and comprehensive list of tools available through WebLicht, please log in to the WebLicht website.
Sentence splitting and tokeniztation are usually understood as a way of segmenting texts rather than transforming them or adding feature information. Each segment, be it a sentence or a token, corresponds to a particular sequence of lower level elements (tokens or characters) that forms, for the purposes of further research or processing, a single unit. Segementing digital texts can be complicated, depending on the language of the text and the linguistic considerations that go into processing it.
Sentence splitters, sometimes called sentence segmenters, split text up into individual sentences with unambiguous delimiters.
Recognizing sentence boundaries in texts sounds very easy, but it can be a complex problem in practice. Sentences are not clearly defined in general linguistics, and sentence-splitting programs are driven by the punctuation of texts and the practical concerns of computational linguistics, not by linguistic theory.
Punctuation dates back a very long time, at least to the 9th century BCE. The Meša Stele – an inscribed stone found in modern Jordan describing the military campaigns of the Moabite king Meša – is the oldest attestation of different punctuation marks to indicate word separation and grammatical phrases [Compston1919], [Martens 2011]. Until modern times though, not all written languages used punctuation. The idea of dividing written texts into individual sentences using some form of punctuation is an invention of 16th century Italian printers and did not reach some parts of the world until the mid-20th century. This makes it very difficult to develop historical language corpora compatible with tools based on modern punctuation. Adding punctuation to old texts is time-consuming and researchers of different schools will not always agree on where the punctuation belongs.
In many languages – including most European languages – sentence delimiting punctuation has multiple functions other than just marking sentences. The period often marks abbreviations as well as being used to write ordinal numbers or to split large numerical expressions in groups of three digits. Sentences can also end with a wide variety of punctuation other than the period. Question marks, exclamation marks, ellipses (dropped words), colons, semi-colons and a variety of other markers must have their purpose in specific contexts correctly identified before they can be confidently considered sentence delimiters. Additional problems arise with quotes, URLs and proper nouns that incorporate non-standard punctuation. Furthermore, most texts contain errors and inconsistencies of punctuation that simple algorithms cannot easily identify or correct.
Sentence splitters are often integrated into tokenizers, but some separate tools are available including:
A splitter for English that can be trained for other languages.
A splitter for English, but quite effective in other languages that use similar punctuation.
A splitter for English that can be trained for other languages.
A token is a unit of language similar to a word but not quite the same. In computational linguistics it is often more practical to discuss tokens instead of words, since a token encompasses many linguistically irrelevant and / or defective elements found in actual texts (numbers, abbreviations, punctuation, etc.) and avoids many of the complex theoretical considerations involved in talking about words.
In modern times, most languages have writing systems derived from ancient languages used in the Middle East and by traders on the Mediterranean Sea starting about 3000 years ago. The Latin, Greek, Cyrillic, Hebrew and Arabic alphabets are all derived from a common ancient source – a variety of Phoenician widely used in trade and diplomacy – and most historians think that the writing systems of India and Central Asia come from the same origin. See [Fischer 2005] and [Schmandt-Besserat 1992] for fuller histories of writing.
All of the writing systems derived from ancient Phoenician use letters that correspond to specific sounds. When words are written with letters that represent sounds, words can only be distinguished from each other if set apart in some way, or if readers slowly sound the letters out to figure out where the pauses and breaks are. The first languages to systematically use letters to represent sounds usually separated text into word-like units with a mark of some kind – generally a bar (“|”) or a double-dot mark much like a colon (“:”). However, these marks were used inconsistently and many languages with alphabets stopped using explicit markers over time. Latin, Greek, Hebrew and the languages of India were not written with any consistent word marker for many centuries. Whitespaces between words were introduced in western Europe in the 12th century, probably invented by monks in Britain or Ireland, and spread slowly to other countries and languages [Saenger 1997]. Since the late 19th century, most languages – all but a few in Pacific Asia – have been written with regular spaces between words.
For those languages, much but far from all of the work of tokenizing digital texts is performed by whitespace characters and punctuation. The simplest tokenizers just split the text up by looking for whitespace, and then separate punctuation from the ends and beginnings of words. But the way those spaces are used is not the same in all languages, and relying exclusively on spaces to identify tokens does not, in practice, work very well. Tokenization can be very complicated because tokens do not always match the locations of spaces.
Compound words exist in many languages and often require more complex processing. The German word Telekommunikationsvorratsdatenspeicherung (“telecommunications data retention”) is one case, but English has linguistically similar compounds like low-budget and first-class. Tokenizers – or sometimes similar tools that may be called decompounders or compound splitters – are often expected to split such compounds up, or are expected to only split some of them up. Whether or not compounds should be split may depend on further stages of processing. For syntactic parsing of German, for example, it is often undesirable because compounds are treated syntactically and morphologically like a single word, i.e., plurals and declinations only change the end of the whole compound and parsers can recognize parts-of-speech from the final part of the compound. In French, the opposite is often true and compounds like arc-en-ciel (“rainbow”) and cannot be treated as single words because pluralization modifies the middle of the compound (arcs-en-ciel). For information retrieval, in contrast, German words are almost always decompounded, because a search for Vorratsdatenspeicherung (“data retention”) should match documents containing Telekommunikationsvorratsdatenspeicherung. In French, however, no one would want arc (“arch”, “arc”, or “bow”) or ciel (“sky” or “heaven”) to match arc-en-ciel. English has examples of both kinds of compounds, with words like houseboats that behave like German compounds, but also parts-of-speech, which behave like French ones.
In other cases, something best treated as a single token may appear in text as multiple words with spaces, like New York. There are also ambiguous compounds, where they may sometimes appear as separate words and sometimes not. Egg beater, egg-beater and eggbeater are all possible in English and mean the same thing.
Short phrases that are composed of multiple words separated by spaces may also sometimes be best analyzed as a single word, like the phrase by and large or pain in the neck in English. These are called multi-word terms and may overlap with what people usually call idioms.
Contractions like I'm and don't also pose problems, since many higher level analytical tools like part-of-speech taggers and parsers may require them to be broken up, and many linguistic theories treat them as more than one word for grammatical purposes.
Phrasal verbs in English and separable verbs in German are another category of problem for tokenizers, since these are often best treated as single words, but are separated into parts that may not appear next to each other in texts. For example:
When we love others, we naturally want to talk about them, we want to show them off, like emotional trophies. (Alexander McCall Smith, Friends, Lovers, Chocolate)
Die Liebe im Menschen spricht das rechte Wort aus. (“People's love utters the right word.”, Ferdinand Ebner, Schriften, vol. 2.)
Verbs like to show off in English and aussprechen in German often require treatment as single words, but in the examples above, appear not only as separate words, but with other words between their parts. Simple programs that just look for certain kinds of characters cannot identify these structures as tokens.
Which compounds, if any, should be split, and which multi-part entities should be processed as a single token, depends on the language of the text and the purpose of processing. Consistent tokenization is generally related to identifying lexical entities that can be looked up in some lexical resource and this can require very complex processing for ordinary texts. Its purpose is to simplify and remove irregularities from the data for the benefit of further processing. Since the identification of basic units in text must precede almost all kinds of further processing, tokenization is the first or nearly the first thing done for any linguistic processing task.
Additional problems can arise in some languages. Of major modern languages, only Chinese, Japanese and Korean currently use writing systems not thought to be derived from a common Middle Eastern ancestor, and they do not systematically mark words in ordinary texts with spaces or any other visible marker. Several southeast Asian languages – Thai, Lao, Khmer and some other less widely spoken languages – still use no spaces today or use them rarely and inconsistently despite having writing systems derived from those used in India. Vietnamese – which is written with a version of the Latin alphabet today, but used to be written like Chinese – places spaces between every syllable, so that even though it uses spaces, they are of little value in tokenization. Tokenization in these languages is a very complex process that can involve large dictionaries and sophisticated machine learning procedures.
As mentioned in the previous section, tokenization is often combined with sentence-splitting in a single tool. Some examples for implementations of tokenizers are:
A tokenizer for English and German that includes an optional sentence splitter (see the section called “Sentence splitters”).
A tokenizer for German, English, French, Italian, Czech, Slovenian, and Hungarian that includes a sentence splitter (see the section called “Sentence splitters”).
A tokenizer for English text (part of the Stanford CoreNLP tool).
Part-of-speech taggers (PoS taggers) are programs that take tokenized text as input and associate a part-of-speech tag (PoS tag) with each token. A PoS tagger uses a specific, closed set of parts-of-speech – usually called a tagset in computational linguistics. Different taggers for different languages will routinely have different, sometimes radically different, tagsets or part-of-speech systems. For some languages, however, de-facto standards exist in the sense that most part-of-speech taggers use the same tagset. In German, for example, the STTS tagset is very widespread, but in English several different tagsets are in regular use, like the Penn Treebank tagset and several versions of the CLAWS tagset.
A part-of-speech is a category that abstracts some of the properties of words or tokens. For example, in the sentence The dog ate dinner there are other words we can substitute for dog and still have a correct sentence, words like cat or man. Those words have some common properties and belong to a common category of words. PoS schemes are designed to capture those kinds of similarities. Words with the same PoS are in some sense similar in their use, meaning, or function.
Parts-of-speech have been independently invented at least three times in the distant past. They are documented to the 5th century BC in Greece, approximately for the same period in India, and from the 2nd century AD in China. There is no evidence to suggest any of these three inventions was copied from other cultures. The origins of parts-of-speech are described in greater detail in [Martens 2011]. The 2nd century BCE Greek grammar text The Art of Grammar outlined a system of nine PoS categories that became very influential in European languages: nouns, verbs, participles, articles, pronouns, prepositions, adverbs, and conjunctions, with proper nouns as a subcategory of nouns. Most PoS systems in use today have been influenced by that scheme.
Modern linguists no longer think of parts-of-speech as a fixed, short list of categories that is the same for all languages. They do not agree about whether or not any of those categories are universal, or about which categories apply to which specific words, contexts and languages. Different linguistic theories, different languages, and different approaches to annotation use different PoS schemes.
Tagsets also differ in the level of detail they provide. A modern corpus PoS scheme, like the CLAWS tagset used for the British National Corpus, can go far beyond the classical nine parts-of-speech and make dozens of fine distinctions. CLAWS version 7 has 22 different parts-of-speech for nouns alone. Complex tagsets are usually organized hierarchically, to reflect commonalities between different classes of words.
Examples of widely used tagsets include STTS for German [Schiller et al. 1999], the Penn Treebank Tagset for English [Santorini 1990], and the CLAWS tagset for English [Garside et al. 1997]. Most PoS tagsets were devised for specific corpora, and are often inspired by older corpora and PoS schemes. PoS taggers today are almost all tools that use machine learning and have been specifically trained for the language and tagset they use. They can usually be retrained for new tagsets and languages.
PoS taggers almost always expect tokenized texts as input, and it is important that the tokens in texts match the ones the PoS tagger was trained to recognize. As a result, it is important to make sure that the tokenizer used to preprocess texts matches the one used to create the training data for the PoS tagger.
Another important factor in the development of PoS taggers is their handling of out-of-vocabulary words. A significant number of tokens in any large text will not be recognized by the tagger, no matter how large a dictionary they have or how much training data was used. PoS taggers may simply output a special “unknown” tag, or may guess what the right PoS should be given the remaining context. For some languages, especially those with complex systems of prefixes and suffixes for words, PoS taggers may use morphological analyses to try to find the right tag.
Implementations of PoS taggers include:
A PoS tagger for German, English, French, Italian, Dutch, Spanish, Bulgarian, Russian, Greek, Portuguese, Chinese, Swahili, Latin, Estonian and old French, and trainable for many others.
A PoS tagger for English and German distributed as part of the Apache OpenNLP toolkit.
A PoS tagger for English distributed as part of the Stanford Core NLP toolkit.
A PoS tagger for English, Danish, Dutch and Norwegian (Nynorsk).
Morphology is the study of how words and phrases change in form depending on their meaning, function and context. Morphological tools sometimes overlap in their functions with PoS taggers and tokenizers.
Because linguists do not always agree on what is and is not a word, different linguists may disagree on what phenomena are part of morphology, and which ones are part of syntax, phonetics, or other parts of linguistics. Generally, morphological phenomena are considered either inflectional or derivational depending on their role in a language.
Inflectional morphology is the way words are required to change by the rules of a language depending on their syntactic role or meaning. In most European languages, many words have to change form depending on the way they are used.
How verbs change in form is traditionally called conjugation. In English, present tense verbs have to be conjugated depending on their subjects. So we say I play, you play, we play and they play but he plays and she plays. This is called agreement, and we say that in English, present tense verbs must agree with their subjects, because the properties of whatever the subject of the verb is determine the form the verb takes. But in the past tense, English verbs have to take a special form to indicate that they refer to the past, but do not have to agree. We say I played and he played.
Languages can have very complex schemes that determine the forms of verbs, reflecting very fine distinctions of meaning and requiring agreement with many different features of their subjects, objects, modifiers or any other part of the context in which they appear. These distinctions are sometimes expressed by using additional words (usually called auxiliaries or sometimes helper words), and sometimes by prefixes, suffixes, or other changes to words. Many languages also combine schemes to produce potentially unlimited variations in the forms of verbs.
Nouns in English change form to reflect their number: one dog but several dogs. A few words in English also change form based on the gender of the people they refer to, like actor and actress. These are rare in English but common in most other European languages. In most European languages, all nouns have an inherent grammatical gender and any other word referring to them may be required to change form to reflect that gender.
In many languages, nouns also undergo much more complex changes to reflect their grammatical function. This is traditionally called declension or a case. In the German sentence Das Auto des Lehrers ist grün (“The teacher's car is green”), the word Lehrer (“teacher”) is changed to Lehrers because it is being used to say whose car is meant.
Agreement is often present between nouns and words that are connected to them grammatically. In German, nouns undergo few changes in form when declined, but articles and adjectives used with them do. Articles and adjectives in languages with grammatical gender categories usually must also change form to reflect the gender of the nouns they refer to. Pronouns, in most European languages, also must agree with the linguistic properties of the things they refer to as well as being declined or transformed by their context in other ways.
The comparative and superlative forms of adjectives – safe, safer, safest is one example – are also usually thought of as inflectional morphology.
Some languages have very complex inflectional morphologies. Among European languages, Finnish and Hungarian are known to be particularly complex, with many forms for each verb and noun, and French is known for its complex rules of agreement. Others are very simple. English nouns only vary between singular and plural, and even pronouns and irregular verbs like to be and to have usually have no more than a handful of specific forms. Some languages (mostly not spoken in Europe) are not thought of as having any inflectional morphological variation at all.
Just because a word has been inflected does not mean it is a different word. In English, dog and dogs are not different words just because of the -s added to indicate the plural. For each surface form, there is a base word that it refers to, independently of its morphology. This underlying abstraction is called its lemma, from a word the ancient Greeks used to indicate the “substance” of a word. Sometimes, it is called the canonical form of a word, and indicates the spelling you would find in a dictionary (see the section called “Lexical resources”).
One source of ambiguity that lemmatizers and morphological analyzers may be expected to resolve is that a particular token may be an inflected form of more than one lemma. In English, for example, the word tear can refer to the noun meaning “a secretion of water from someone's eyes”, or to the verb that means “to pull something apart”, among other possible meanings. Seen in isolation, tear and tears could refer to either, but tearing usually can only refer to a verb. Most – pratically all – languages have similar cases, i.e. German die Schale meaning either the bowl (singular) or the scarves (plural). Disambiguation can involve many sorts of information other than just the forms of the words, and may use complex statistical information and machine learning. Many annotated corpora systematically disambiguate lemmas as part of their mark-up.
Inflectional morphology in European languages most often means changing the endings of words, either by adding to them or by modifying them in some way, but it can involve changing any part of a word. In English, some verbs are inflected by changing one or more of their vowels, like break, broke, and broken. In German many common verbs – called the strong verbs – are inflected by changing the middle of the word. In Arabic and Hebrew, all nouns and verbs and many other words are inflected by inserting, deleting, and changing the vowels in the middle of the word. In the Bantu languages of Africa, words are inflected by adding prefixes and changing the beginnings of words. Other languages indicate inflection by inserting whole syllables in the middle of words, repeating parts of words, or almost any other imaginable variation. Many languages use more than one way of doing inflection.
Derivational morphology is the process of making a word from another word, usually changing its form while also changing its meaning or grammatical function in some way. This can mean adding prefixes or suffixes to words, like the way English constructs the noun happiness and the adverb unhappily from the adjective happy. These kinds of processes are often used to change the part-of-speech or syntactic functions of words – making a verb out of a noun, or an adjective out of an adverb, etc. But sometimes they are used only to change the meaning of a word, like adding the prefix un- in both English and German, which may negate or invert the meaning of a word in some way but does not change its grammatical properties or part-of-speech.
As with inflectional morphology, languages may use almost any kind of variation to derive new words from old ones, not just prefixes and suffixes. There is no simple, fixed line to separate derivational morphology from inflectional morphology, and individual linguists will sometimes disagree about how to categorize individual word formation processes. A few will disagree about whether there is any meaningful distinction between inflection and derivation at all.
One common derivational process found in many different languages is to make compound words. German famously creates very long words this way, and English has many compound constructs that are sometimes written as one word, or with a hyphen, or as separate words that people understand to have a single common meaning. The opposite process – splitting a single word into multiple parts – also exists in some languages. Phrasal verbs in English and separable verbs in German are two examples (see the section called “Tokenizers”), and a morphological analyzer may have to identify those constructions and handle them appropriately.
One of the oldest and simplest tools for computational morphological analysis is the stemmer. The term stem refers to the part of a word that is left over when inflectional and derivational prefixes and suffixes have been stripped from a word, and the parts of words left when a compound word has been split into its parts. Many words share a common “stem” like the German words sehen, absehen, absehbar and Sehhilfe, which all share the stem seh. This stem usually reflects a common meaning.
The ability to reduce groups of similar words to a common form corresponding to a common meaning made stemmers attractive for information retrieval applications. Stemmers are algorithmitically very simple and typically use a catalog of regular expressions – simple patterns of letters – for identifying and stripping inflectional and derivative elements. They are not very linguistically sophisticated, and miss many kinds of morphological variation. Whenever possible, more sophisticated tools should be used.
However, stemmers are relatively easy to make for new languages and are often used when better tools are unavailable. The Porter stemmer is the classical easy-to-implement algorithm for stemming [Porter 1980].
Lemmatizers are programs that take tokenized texts as input and return a set of lemmas or canonical forms. They usually use a combination of rules for decomposing words and a dictionary, sometimes along with statistical rules and machine learning to disambiguate homonyms. Some lemmatizers also preserve some word class information, like noting that a word ends in an -s that was removed, or an -ing – usually just enough to reconstruct the original token, but not as much as a full morphological analysis.
Implementations of lemmatizers:
SMOR is a stand-alone lemmatizer for German that also includes an optional morphological analysis module (see the section called “Morphological analyzers”).
The RACAI lemmatizer works for Romanian, English and French texts.
MorphAdorner is a lemmatizer for English written in the Java programming language.
Full morphological analyzers take tokenized text as input and return complete information about the inflectional categories each token belongs to, as well as their lemma. They are often combined with PoS taggers and sometimes with syntactic parsers, because a full analysis of the morphological category of a word usually touches on syntax and almost always involves categorizing the word by its part-of-speech.
Some analyzers may also provide information about derivational morphology and break up compounds into constituent parts.
High-quality morphological analyzers almost always use large databases of words and rules of composition and decomposition. Many also employ machine learning techniques and have been trained on manually analyzed data. Developing comprehensive morphological analyzers is very challenging, especially if derivational phenomena are to be analyzed.
Implementations of morphological analyzers:
A morphological analyzer for English.
Syntax is the study of the connections between parts of sentences. It is intended to account for the meaningful aspects of the ordering of words and phrases in language. The principles that determine which words and phrases are connected, how they are connected, and what effect that has on the ordering of the parts of sentences are called a grammar.
There are many different theories of syntax and ideas about how syntax works. Individual linguists are usually attached to particular schools of thought depending on where they were educated, what languages and problems they work with, and to a large degree their personal preferences.
Most theories of syntax fall into two broad categories that reflect different histories, priorities and theories about how language works: dependency grammars and constituency grammars. The divide between these two approaches dates back to their respective origins in the late 1950s, and the debate between them is still active. Both schools of thought represent the connections within sentences as trees or directed graphs, and both schools agree that representing those connections requires that implicit structural information is made explicit. Relationships between words cannot be trivially represented as a sequence of tokens, and designing software that recognizes those relationships in texts is a challenging problem.
In dependency grammars, connections are usually between words or tokens, and the edges that join them have labels from a small set of connection types determined by some theory of grammar. Figure 7.2, “A dependency analysis” is a dependency analysis from a particular dependency grammar theory.
Dependency grammars tend to be popular among people working with languages in which word order is very flexible and words are subject to complex morphological agreement rules. It has a very strong tradition in Eastern Europe, but is also present elsewhere to varying degrees in different countries.
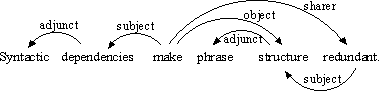 |
A dependency analysis of the sentence Syntactic dependencies make phrase structure redundant. This analysis uses the Word Grammar framework and is taken from the Word Grammar website.
Constituency grammars view the connections between words as a hierarchal relationship between phrases. They break sentences up into parts, usually but not always continuous ones, and then break each part up into smaller parts, until they reach the level of individual tokens. The trees drawn to demonstrate constituency grammars reflect this structure. Edges in constituency grammars are not usually labeled.
Constituency grammar draws heavily on the theory of formal languages in computer science, but tends to use formal grammar in conjunction with other notions to better account for phenomena in human language. For example, there are prominent theories of syntax that include formalized procedures for tree rewriting, type hierarchies and higher-order logics, among other features. Few linguists currently believe the theory of formal languages alone can account for syntax.
As a school of thought, constituency grammar is historically associated with the work of Noam Chomsky and the American linguistic tradition. It tends to be popular among linguists working in languages like English, in which morphological agreement is not very important and word orders are relatively strictly fixed. It is very strong in English-speaking countries, but is also present in much of western Europe and to varying degrees in other parts of the world. See Figure 7.3, “A constituency analysis” for an example of a constituency analysis of an English sentence.
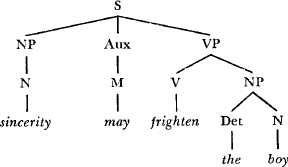 |
A constituency analysis of the sentence Sincerity may frighten the boy. This analysis is taken from [Chomsky1965].
The labels on edges in Figure 7.2, “A dependency analysis” and on tree nodes in Figure 7.3, “A constituency analysis” form a part of the specific syntactic theories from which these examples are drawn. Fuller explanations for them and their meanings are to be found in the referenced texts. Specific syntactic parsers and linguistic tools may use entirely different labels based on different ideas about language, even when the general form of the syntactic representations they generate resemble the examples here.
Among computational linguists and people working in natural language processing, there is a growing tendency to use hybrid grammars that combine elements of both the constituency and dependency traditions. These grammars take advantage of a property of constituency grammars called headedness. In many constituency frameworks, the phrases identified by the grammar have a single constituent that is designated as its head. A constituency analysis where all phrases have heads, and where all edges have labels, is broadly equivalent to a dependency analysis.
Figure 7.4, “A hybrid syntactic analysis” is a tree from the TüBa-D/Z treebank of German, and its labels are explained in [Hinrichs 2004]. This treebank uses a hybrid analysis of sentences, containing constituents that often have heads and edges with dependency labels. As with many hybrid analyses, not all constituents have heads, and some edges have empty labels, so it is not completely compatible with a strict dependency framework. However, the added information in the edges also makes it incompatible with a strict constituency framework. This kind of syncretic approach tends to find more acceptance in corpus and computational linguistics than in theoretical linguistics.
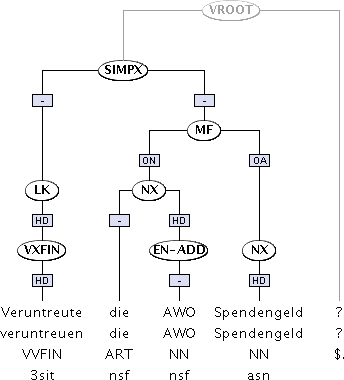 |
A hybrid syntactic analysis of the German sentence Veruntreute die AWO Spendengeld? Display provided by the TIGERSearch application [Lezius 2002].
Syntactic parsing is the process (either automated or manual) of performing syntactic analysis. A computer program that parses natural language is called a parser. Superficially, the process of parsing natural language resembles parsing in computer science – the way a computer makes sense of the commands users type at command lines, or enter as source code for programs – and computing has borrowed much of its vocabulary for parsing from linguistics. But in practice, natural language parsing is a very different undertaking.
The oldest natural language parsers were constructed using the same kinds of finite-state grammars and recognition rules as parsing computer commands, but the diversity, complexity and ambiguity of human language makes those kinds of parsers difficult to construct and prone to failure. The most accurate and robust parsers today incorporate statistical principles to some degree, and have often been trained from manually parsed texts using machine learning techniques.
Parsers usually require some preprocessing of the input text, although some are integrated applications that perform preprocessing internally. Generally, the input to a parser must have sentences clearly delimited and must usually be tokenized. Many common parsers work with a PoS-tagger as a preprocessor, and the output of the PoS-tagger must use the tags expected by the parser. When parsers are trained using machine learning, the preprocessing must match the preprocessing used for the training data.
The output of a parser is never simply plain text – the data must be structured in a way that encodes the connections between words that are not next to each other.
Implementations of parsers:
A constituency parser for English, German and many other languages. This parser optionally creates hybrid dependency output.
A constituency parser for English.
A constituency parser for German and English.
A dependency parser for English, German, Spanish and Chinese that is part of the Mate tools.
A hybrid parser for Dutch.
High-quality parsers are very complex programs that are very difficult to construct and may require very powerful computers to run or may process texts very slowly. For many languages there are no good automatic parsers at all.
Chunkers, also known as shallow parsers, are a more lightweight solution [Abney1991]. They provide a partial and simplified constituency parse, often simply breaking sentences up into clauses by looking for certain kinds of words that typically indicate the beginning of a phrase. They are much simpler to write, more robust, and much less resource-intensive to run than full parsers, and are available in many languages.
Implementations of chunkers:
A chunker for Romanian and English.
A chunker for English written in the Java programming language.
Words can have more than one meaning. For example, the word glass can refer to a “drinking glass” and to the “material substance glass”. People can usually figure out, given the context of a word, which of a word's many meanings are intended, but this is not so easy for a computer. The automatic identification of the correct meaning of a word in context (sometimes called its sense) is called word-sense disambiguation (WSD).
Automatic WSD usually uses a combination of a digitized dictionary – a database of words and possible meanings – and information about the contexts in which words are likely to take particular meanings. Programs that do this often employ machine learning techniques and training corpora. Inputs to WSD programs are usually tokenized texts, but sometimes PoS tagging and even parsing may be required before disambiguation.
An implementation of a WSD tool:
A graph based WSD and word sense similarity toolkit for English.
Coreferences occur when two or more expressions refer to the same thing. Usually, linguists talk about coreferences only in those cases where the syntactic and morphological rules of the language do not make it clear that those expressions necessarily refer to the same thing. Instead, speakers have to use their memory of what has already been said, and their knowledge of the real world context of communication, to determine which words refer to the same thing and which ones do not.
An anaphoric expression is a particular case of coreference that can be resolved by identifying a previous expression that refers to the same thing. For example, in the sentence The car stalled and it never started again the word it refers to the car. But in the sentence The car hit a truck and it never started again it is not clear whether it refers to the car or the truck. In the sentences John was out with Dave when he saw Mary. He thought Mary saw him, but she ignored him completely. it is not clear whether any instance of he and him refers to John or Dave.
These kinds of ambiguities are what coreference resolution addresses. They can be very important in many NLP applications, like information retrieval and machine translation. Few automatic tools exist to resolve these kinds of problems and most use some form of machine learning.
Implementations for coreference resolution are:
A machine learning tool for coreference resolution. Currently supports English, Italian and German but may be trainable for other languages.
A coreference resolver designed for the CoNLL 2012 coreference shared task.
Named entities are a generalization of the idea of a proper noun. They refer to names of people, places, brand names, non-generic things, and sometimes to highly subject-specific terms, among many other possibilities. There is no fixed limit to what constitutes a named entity, but these kinds of highly specific usages form a large share of the words in texts that are not in dictionaries and not correctly recognized by linguistic tools. They can be very important for information retrieval, machine translation, topic identification and many other tasks in computational linguistics.
NER tools can be based on rules, on statistical methods and machine learning algorithms, or on combinations of those methods. The rules they apply are sometimes very ad hoc – like looking for sequences of two or more capitalized words – and do not generally follow from any organized linguistic theory. Large databases of names of people, places and things often form a part of an NER tool.
NER tools sometimes also try to classify the elements they find. Determining whether a particular phrase refers to a person, a place, a company name or other things can be important for research or further processing.
A special application of NER is geovisualization – the identification of place names and their locations. Knowing that a named entity refers to a particular place can make it much easier for computers to disambiguate other references. A reference to Bismarck near a reference to a place in Germany likely refers to the 19th century German politician Otto von Bismarck, but near a reference to North Dakota, it likely refers to the small American city of Bismarck.
Implementations of NER tools:
A NER tool for German based on the Stanford Named Entity Recognizer.
A NER tool for English distributed as part of the Stanford Core NLP toolkit.
A NER tool for German trained from large corpora and Wikipedia data.
Aligners are tools mostly used with bilingual corpora – two corpora in different languages where one is a translation of the other, or both are translations from a single source. Statistical machine translation programs use aligned corpora to learn how to translate one language into another.
Alignments can be at different levels. Sentence aligners match the sentences in the two corpora, while word aligners try to align individual words. These programs are usually statistical in nature, and are typically language independent.
Implementations of aligners:
| |  | |
| Technical issues in linguistic tool management |  | ToC | ToC | Manual annotation and analysis tools |