| WebLicht – A service-oriented architecture for linguistic resources and tools | ||
|---|---|---|
 | Chapter 8. Web services: Accessing and using linguistic tools |  |
| WebLicht – A service-oriented architecture for linguistic resources and tools | ||
|---|---|---|
| | Chapter 8. Web services: Accessing and using linguistic tools | |
WebLicht (Web-based Linguistic Chaining Tool) is a web application built on service-oriented architecture principles that offers users access to linguistic resources. It incorporates a variety of new technologies to provide a single, user-friendly interface to a growing collection of tools and corpora. WebLicht is accesible from any Internet-connected computer with a recent web browser. Figure 8.1, “ The WebLicht user interface, displayed in a browser” is a screenshot of the WebLicht user interface, displayed in an ordinary web browser. No special software needs to be installed on user's computers and WebLicht has no particular system requirements beyond those of standard web browser software.
WebLicht services can also be accessed directly from user-created and third party applications that support the required protocols, although at present there are no such applications. This is one of the principles of web service development and service-oriented architectures.
This section will describe the WebLicht system and its functioning.
WebLicht is organized around the notion of a tool chain, a succession of tools which
work in a sequence on the same data,
take the output of the preceding tool as their input,
add information to these input data in a cumulative way, and
do not alter either the primary data nor the data which were added by preceding tools.
Many linguistic tools perform specific and well-defined tasks, and for any particular task, there may be a variety of tools that do the same task but differ in underlying algorithm, basis in linguistic theory, or target language. The hierarchal nature of linguistic processing (see Chapter 7, Linguistic tools) means many tools rely on lower level tools to function. The “chain of tools” concept follows from this situation, and WebLicht offers users a robust and user-friendly way to assemble these small tools into processes.
For example, to parse a corpus, the user first uploads a corpus using their browser or selects a corpus already stored by WebLicht, if necessary selecting a format converter as the first tool in the processing chain to import it into the TCF format used internally by WebLicht (see the section called “Interoperability and the Text Corpus Format”). Currently, WebLicht provides format coverters for plain text, RTF and Microsoft Word input.
From the menu, users then select tools one after another, organizing them into a processing chain that performs the required steps to parse the corpus: Tokenizing, then lemmatizing, performing part-of-speech tagging, morphological analysis, and parsing. WebLicht verifies that the input requirements for each tool are satisfied by the previous tools in the chain. For example, it ensures that the tagset used for part-of-speech tagging matches the tag set required as input for a parser. WebLicht's internal processing format guarantees that the ouput of each tool requires no additional formal conversion to be compatible with the next tool in the chain. For additional examples of using WebLicht and constructing tool chains, see the section called “WebLicht usage scenarios”.
Processes can be very long and complex and take time to run. WebLicht provides computing resources to complete the task, without reducing the user's ability to perform other tasks on their computer.
For various reasons, some tools cannot be combined. Many tools have specific input requirements that other tools do not meet, for example a parser may require a particular part-of-speech tagset, and no alternative tagger program will do. Also, many combinations of tools may not make any sense, like combining a named entity recognizer with a word sense disambiguation tool. WebLicht ensures that users can only build chains where the input requirements for each tool are satisfied by the output of the previous ones in the chain. As long as the input and output requirements of each service are being met, WebLicht can combine services from different research groups, hosted and running on different servers, into one robust tool chain.
In order for tools provided through WebLicht to exchange data, they must share a common data format. To make sure that all tools are interoperable, WebLicht has implemented a common interchange format for digitized texts: the Text Corpus Format (TCF, [Heid et al. 2010]). Although oriented originally to written language data, TCF has been extended to other media and is intended to provide interoperability between linguistic tools of all types.
TCF is similar in purpose and broadly compatible with LAF and GrAF (see the section called “Exchange and combination of annotations”), but more narrowly designed for use in a web-based service oriented architecture. Because TCF only provides layers for supported tools, and the LAF and GrAF formats are open-ended formats that support arbitrary kinds of annotations, there is not necessarily complete interoperability between these data formats. Conversion may not be lossless, and tools for converting specific annotations are only available where a converter for those specific kinds of annotations has been provided.
Before WebLicht can process linguistic data, it must be encoded in TCF. WebLicht is developing converters for many common linguistic data formats, both for input into WebLicht and to allow users to export their data to exchange formats common in the corpus linguistics community. The CLARIN-D consoritum, and the resource centres in particular, will offer help and can provide standard converters for many commonly used data formats. As more and more tools and resources are integrated into WebLicht, more conversion tools will be available to tool providers.
TCF is used exclusively as internal processing format designed to support efficient data sharing and web service execution. Using TCF ensures interoperability between WebLicht tools and resources. It is strongly recommended that all tools in WebLicht accept input and produce output in TCF format.
TCF is an XML-based stand-off format (see the section called “Inline vs. stand-off annotations”). Annotations are added to linguistic data by appending new sections to already present TCF-encoded data. Whenever a new layer of annotation is introduced into WebLicht, it is encoded as a new layer independent of the existing layers. Using WebLicht to annotate TCF-encoded materials never changes or erases the original data or information added by previous tools in a chain, it only adds new information which further processing can use or ignore.
TCF's multi-layered stand-off annotation ensures that TCF and WebLicht are independent from specific linguistic theories. There are no assumptions about the linguistic theories underlying the data or the annotations added to it. It is equally compatible with all approaches to language, so long as the tools and resources are formally compatible with WebLicht.
Furthermore, TCF's layering model makes it very easy for tool providers to specify which kinds of annotations are a pre-requisite for a specific tools. For example, if a parser requires texts to be PoS tagged using the Penn Treebank format – a common requirement of several English syntactic parsers – WebLicht can check if a section providing PoS annotations in that format is present in the given TCF file.
For many annotation layers, WebLicht offers visualization tools. These tools are available to tool designers and users automatically if their tools output annotations in a compatible TCF layer. They do not have to develop their own visualization schemes.
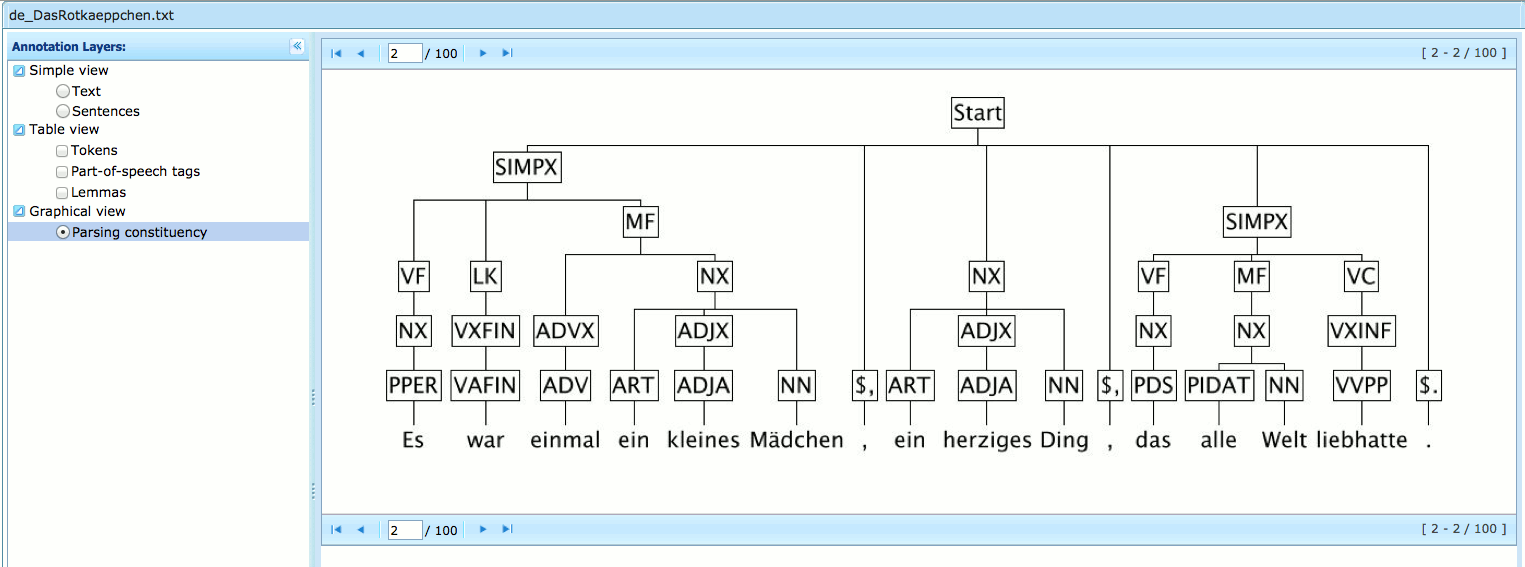
Figure 8.2, “WebLicht constituency parse visualization” is a screenshot of WebLicht displaying a constituency parse tree from a syntactical annotation layer in a TCF file.
Through WebLicht, the CLARIN-D resource centres provide users with information about available services, including details about input requirements and output specifications of each tool. This information is stored as metadata, and every tool integrated into WebLicht must be accompanied by appropriately structured metadata. CMDI metadata descriptions for WebLicht tools must be made available and stored at one of the CLARIN-D data repositories (see the section called “The Component Metadata Initiative (CMDI)”). Tool providers must produce such metadata. The CLARIN-D resource centres offer support and assistance in providing this information and correctly formatting it.
Every web service must also be assigned an individual persistent identifier (PID). PIDs can come from any existing PID assignment system, but they must be unique. Tool providers can also ask for support from a CLARIN-D resource centre in obtaining a PID.
WebLicht is accessible via the Shibboleth SSO system (see the section called “Single Sign-on access to the CLARIN-D infrastructure”). This guarantees that every member of an academic institution which is part of the CLARIN identity federation, can access WebLicht using her institutional account. Furthermore, the SSO infrastructure assures that only members of the academic community can access WebLicht and its web services.
| |  | |
| Service-oriented architectures |  | ToC | ToC | WebLicht usage scenarios |